Make Enterprise Data Agent-Ready
Astra extracts structure, text, tables, charts, maps, images, and language from messy documents — then turns them into JSON, XML, Markdown, and searchable context for AI applications.
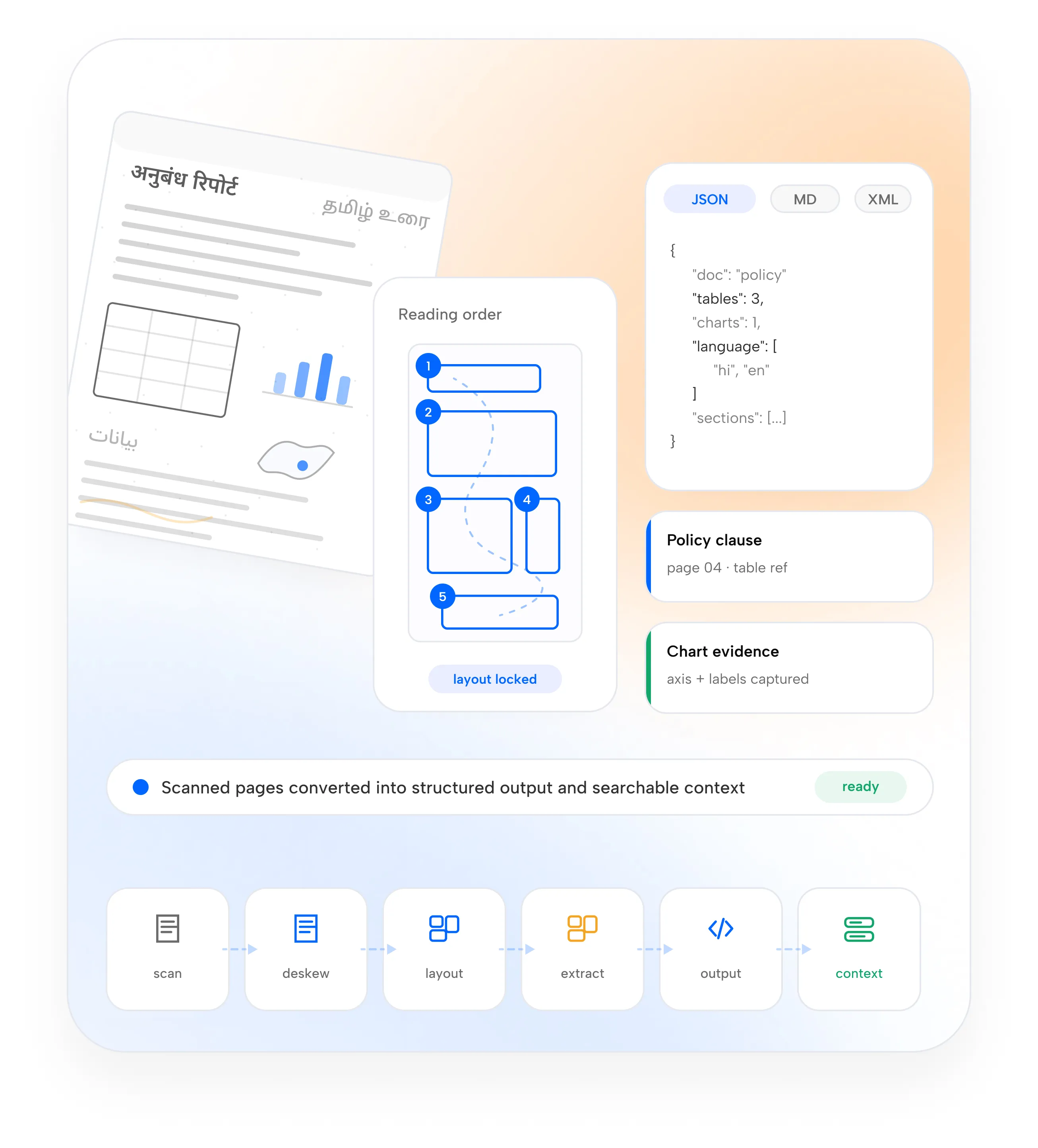
OCR breaks before the work begins.
Real enterprise documents are visual, multilingual, structured, and messy. Plain text extraction loses the information AI systems actually need.
Layout Falls Apart
Columns, titles, captions, footnotes, figures, and sections get flattened into text.
Reading Order Gets Lost
Multi-column pages and mixed layouts are read in the wrong sequence.
Tables Become Text Walls
Rows, columns, merged cells, and headers lose structure.
Visuals Go Unused
Charts, maps, figures, and images are ignored or reduced to empty placeholders.
Scripts Are Misread
Mixed languages, scripts, diacritics, handwriting & low-quality scans create OCR errors.
Errors Are Hard To Fix
One-shot outputs leave teams with no way to review, correct/ apply changes across documents.
From document to structured intelligence.
Astra preserves what matters: layout, hierarchy, reading order, tables, visual elements, language, and source grounding.

Everything needed to make documents AI-ready.
Astra combines visual parsing, multilingual extraction, structured outputs, and review workflows in one system.
Visual Understanding
Layout Detection
Detects titles, paragraphs, lists, tables, figures, charts, maps, images, and document regions.
Visual Hierarchy
Preserves headings, sections, captions, references, footnotes, and semantic grouping.
Reading Order
Reconstructs reading paths across columns, mixed layouts, RTL scripts, and dense pages.
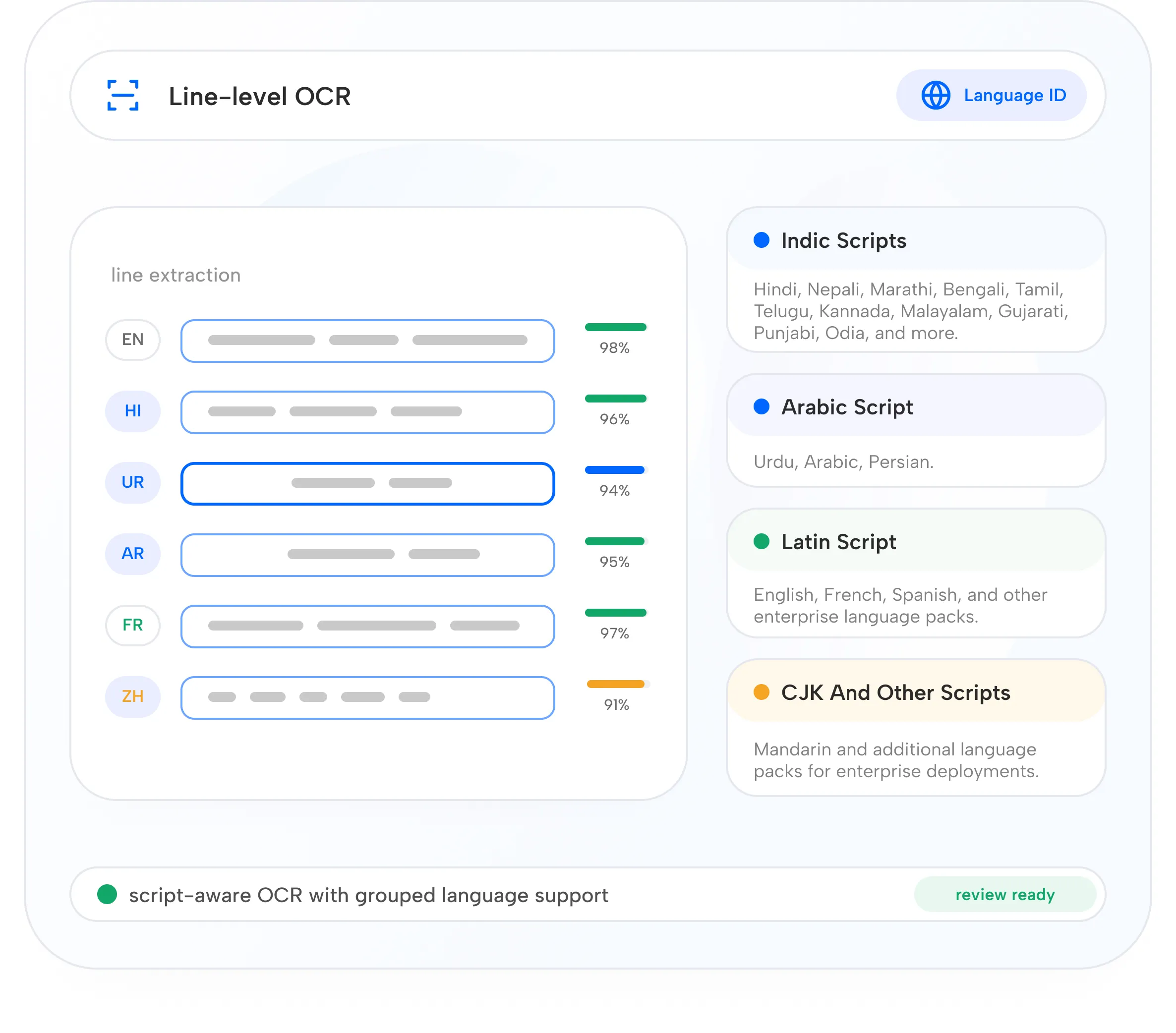
Multilingual Extraction
Text Extraction
Extracts text at line and region level with coordinates, confidence, and language labels.
Language Identification
Identifies languages at region or line level across multilingual pages.
Script-Aware Processing
Handles Indic, Arabic-script, Latin, CJK, and other language packs with routing and review.
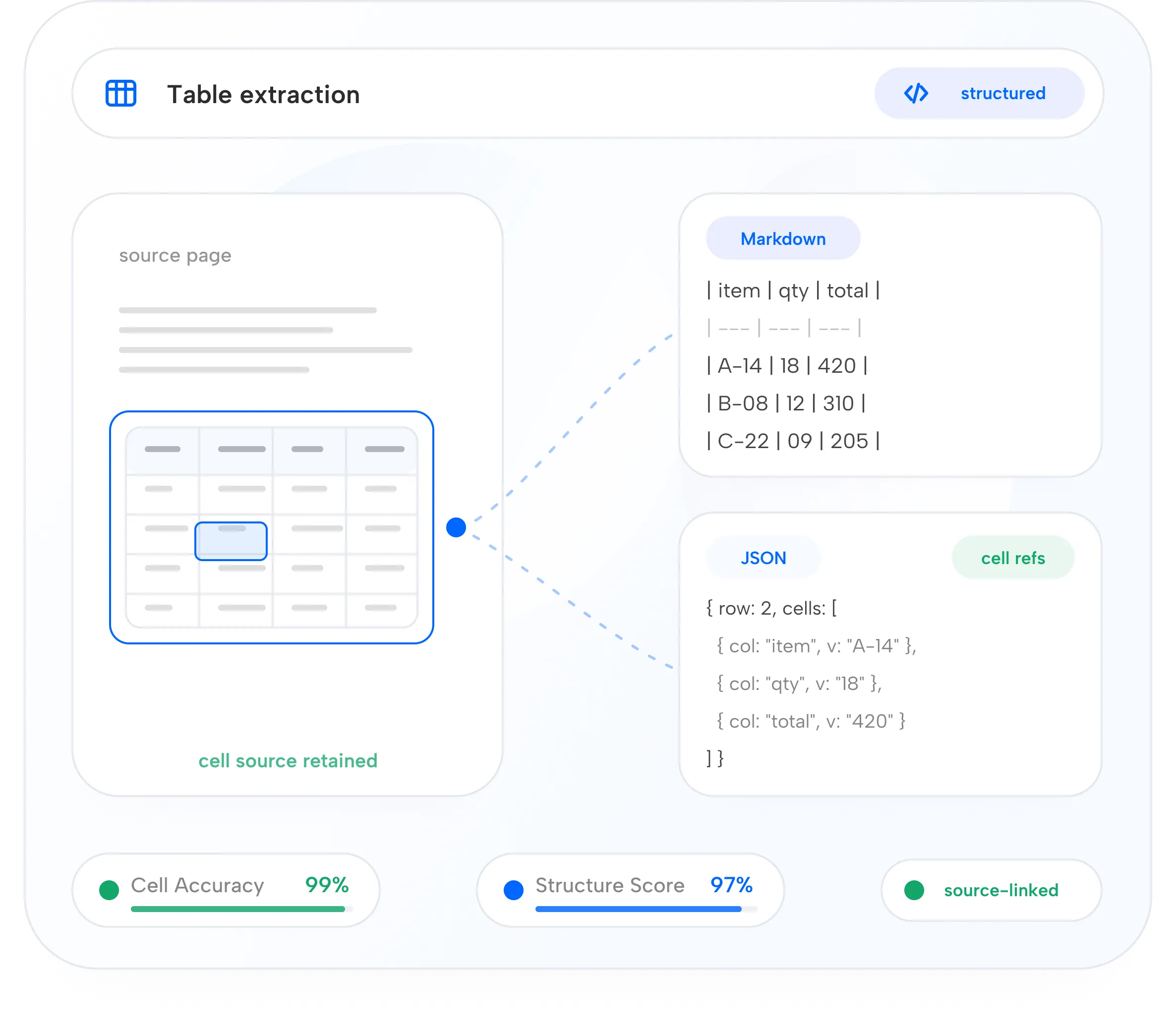
Structured Elements
Table Understanding
Extracts table structure, cells, rows, columns, Markdown, JSON, and descriptions.
Charts And Maps
Describes trends, axes, labels, regions, and visible data in English.
Images And Figures
Generates grounded descriptions and links them back to source regions.
Agent-Ready Output
JSON / XML / Markdown
Exports machine-friendly outputs with source locations and confidence.
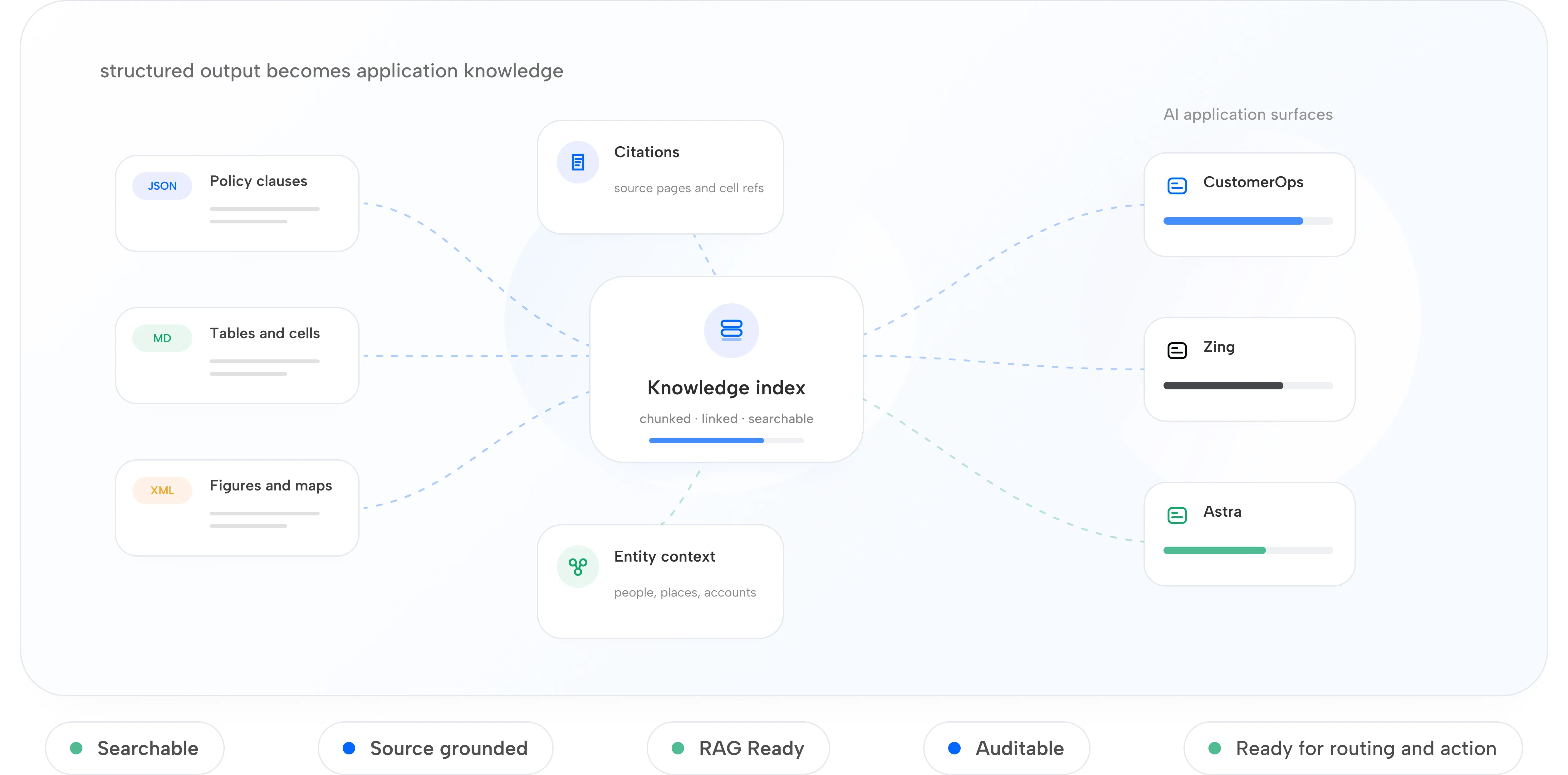
RAG-Ready Chunks
Creates searchable context with hierarchy, citations, and metadata.
Review And Correction
Lets humans or agents correct text, labels, blocks, tables, and structure before export.
Built for multilingual documents.
Astra supports Indian and global language packs, with script-aware extraction, language ID, and review workflows for mixed-language pages.
Every extraction is grounded.
Click any block, cell, line, or description to see where it came from. Review, correct, and apply fixes across the document set.
Extraction is only the first step.
Astra prepares documents for AI applications that search, answer, cite, summarize, route, and act.
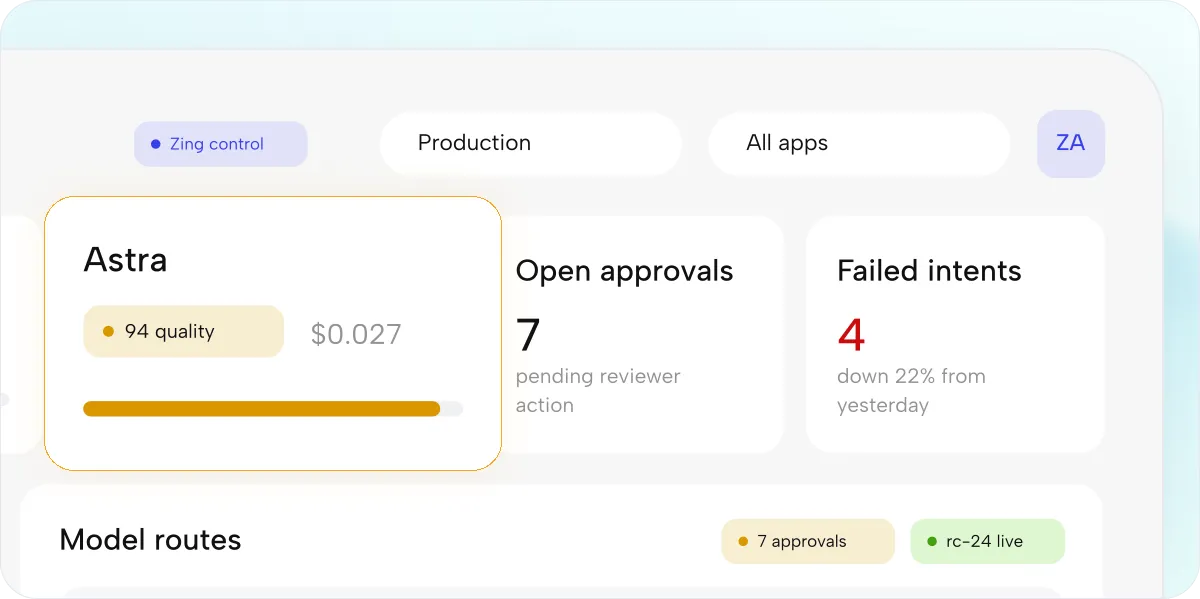
Controlled in Zing.
Monitor extraction quality, route low-confidence blocks to review, manage language packs, track cost, and feed clean context into AI applications.
For documents that carry real work.
Astra is built for teams that need structure, traceability, and multilingual understanding — not just OCR text.
Government & Public Records
Administrative files, archives, forms, maps, reports, and multilingual records.
Finance & Legal
Contracts, statements, filings, court documents, compliance records, and evidence packs.
Healthcare
Forms, reports, claims documents, patient instructions, and scanned records with review controls.
Procurement & Operations
POs, invoices, vendor files, tables, charts, and process documents for downstream workflows.
Publishing & Education
Books, manuscripts, learning materials, newspapers, and archives into searchable structured formats.
Enterprise Knowledge
Internal documents, presentations, reports, and knowledge bases for RAG and agentic workflows.
Use Astra as a platform or an API.
Run document intelligence through a workspace, integrate it into your product, or deploy it inside your enterprise environment.
Astra Workspace
Upload, review, correct, and export document sets through a visual interface.
Astra API
Send files, receive structured outputs, and integrate extraction into your application.
Private Deployment
Run in Zangoh Cloud, private VPC, or on-prem for high-control environments.
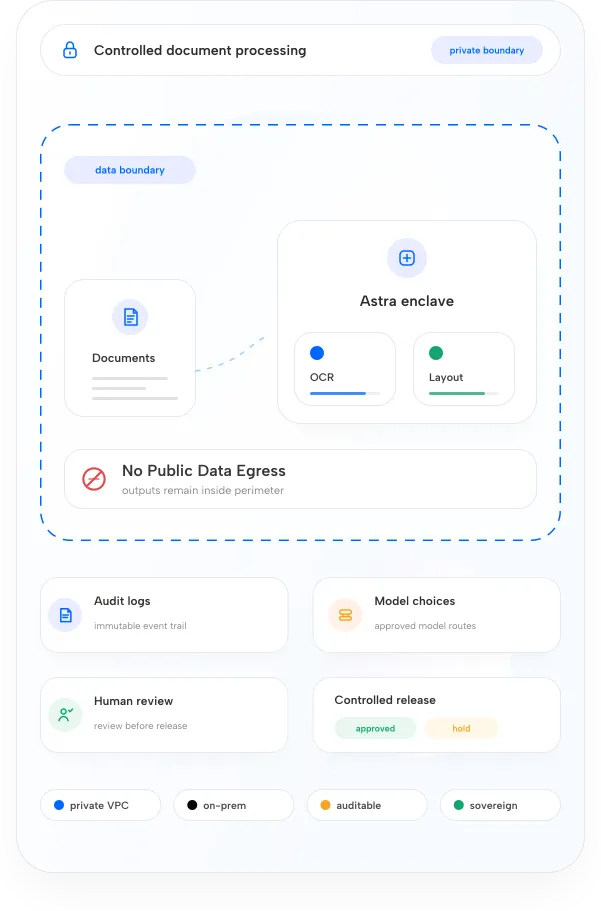
Built for hard documents.
Astra is designed for multilingual, layout-heavy, visually rich, and low-quality documents where simple OCR fails.
Government & Public Records
Layout detection, OCR accuracy, table structure, semantic description, & language ID.
Finance & Legal
Skewed, noisy, blurred, rotated, scanned, mixed-script, and dense layouts.
Healthcare
JSON, XML, Markdown, tables, descriptions, language labels, and coordinates.
Start with one document set.
We'll extract, structure, review, and make it ready for search, RAG, or production AI workflows.